데이터란?
데이터는 정보를 기록하는 데 사용되는 팩트(숫자, 설명, 관측값 등)의 수집 값이다.
데이터를 어떻게 분류할까?
1. 정형 데이터 : 일반적으로 DB(데이터베이스)에서 행과 열로 표시되는 표 구조를 가진 정보이다.
2. 반정형 데이터 : 관계형 DB에는 없지만, 일부 구조를 갖춘 정보이다.
3. 비정형 데이터 : 형식이 없는 오디오나, 비디오, 바이너리(binary, 이진수, 0101101) 구조를 가진 정보이다.
데이터 저장소란?
데이터를 위와 같은 형식을 저장하여 *엔터티의 세부 정보, 특정 이벤트 또는 문서, 이미지 및 기타 형식으로 기록한다.
파일 저장소로 부르기도 하며, 데이터 베이스라고도 한다.
* 엔터티(Entity)란?
실체, 객체라는 의미로,
즉 업무에 필요하고 유용한 정보를 저장하고 관리하기 위한 집합적인 것!
(e.g. 학생의 엔터티는? 학번, 이름, 학년, 생일, 학교 등..)
프로비저닝이란?
데이버베이스 서버를 설정하는 작업이다.
미리 사전으로 설정하는 것!
Provisionoing을 직역하면 "제공하는 것"이다.
어떤 종류의 서비스든 사용자의 요구에 맞게 시스템 자체를 제공하는 것이다!
파일 저장소을 하려면?
4가지 요구사항이 있다.
1. 어디에 저장을 할 거야?
: 컴퓨터에! 카카오톡에! 클라우드에!
2. 저장하려는 데이터 유형이 뭐야?
: 동영상..? 사진? 엑셀파일?
3. 해당 데이터를 읽고, 쓰고, 처리할 수 있는 앱이나 서비스를 갖고 있어?
: 마이크로소프트 엑셀 있어!
4. 사람이 읽을 때 최적화할 거야? 아님 저장이나 처리할 때 최적화 할 거야?
: 다른 사람이 읽어야 하니까 사람이 읽을 때 최적화해 줘.
주요 파일 형식에 대해 알아보자!
1. 구분된 텍스트 파일
가장 일반적인 형식: CSV(필드가 쉼표로 구분이 되고 행이 캐리지 리턴(줄 바꿈)으로 저장된다.
다양한 애플리케이션과 사람이 읽을 수 있는 형식으로 액세스해야 하는 정형 데이터를 저장하는 데에 적합하다.
FirstName, LastName, Email
sooin, Hwang, soo@tistory.com
dupal, guak, guak@google.com
2. JSON(JavaScript Object Notation)
여러 특성을 갖는 데이터 엔터티를 정의하는 데 계층 구조의 문서 *스키마가 사용되는 *유비쿼터스 형식
다양한 애플리케이션과 사람이 읽을 수 있는 형식으로 액세스해야 하는 정형 데이터를 저장하는 데에 적합하다.
*스키마 : 데이터베이스 구조 (어떤 구조로 데이터베이스가 저장되는가?)
*유비쿼터스 : 언제 어디서나 사용할 수 있는 컴퓨터 환경(가상공간, 현실공간)
{
"Students":
[
{
"FirstName" : "Sooin",
"LastName" : "Hwang",
"Contact" :
[
{
"Type" : "Email",
"Address" : "Soo@tistory.com"
}
]
}
]
}
3. XML(Extensible Markup Language)
JSON 전 단계에 사용한 데이터 형식으로 혼화살괄호(../)로 묶인 태그를 사용하여 요소와 특성을 정의
<Students>
<Student FirstName = "Sooin" LastName = "Hwang"/>
<ContactDetails>
<Contact type = "Email" address = "Soo@tistory.com"/>
</ContactDetails>
</Student>
</Students>
4. BLOB(Binary Large Object)
모든 파일을 이진데이터로 저장
단순 텍스트가 아닌 이미지, 사운드, 동영상 등 대용량 바이너리 데이터 저장
01011101110..
5. Avro(행 형식)
데이터 직렬화와 관련된 시스템이며 JSON 형태로 기록
장점:
1. 데이터 타입 쉽게 확인 가능
2. 데이터 압축되어 효율성이 높음
3. 스키마에 대한 설명을 포함하여 구조를 쉽게 이해 가능
4. 데이터를 여러 언어로 액세스 가능
5. 스키마 변경 시 유연하게 대능 가능
6. *Confluent 스키마 레지스트리 사용 가능
* Confluent Schema Registry: Apache Kafka를 기반으로 데이터 스트리밍 플랫폼에서 스키마 관리를 위한 중앙 집중화된 서비스
* Apache Kafka: 실시간으로 기록 스트림을 게시, 구독, 저장 및 처리할 수 있는 분산형 데이터 스트리밍 플랫폼
단점:
1. 디버깅 또는 개발 시 JSON으로 직접 사용할 때 보다 데이터를 쉽게 확인이 불가!
6. ORC(Optimized Row Columnar, 열 형식)
HortonWorks가 Apache Hive에서 읽기 및 쓰기 작업을 최적화하기 위해 개발
특징:
1. 각 태스크의 결과가 하나의 파일로 생성됨 → 네임노드의 부하를 줄여줌
2. datetime, *decimal, complex type(Struct, List, Map, Union)을 지원함
*decimal : 소수(숫자)
3. 파일에 경량 인덱스가 저장됨
- 필터링 조건이 없는 로우 그룹은 스킵,
- 특정 row(열, 가로)로 확인가능
4. 데이터 타입 기반의 block-mode 압축
- integer column(행, 세로)는 run-length encoding을 사용
- 문자열 column은 dictionary encoding 사용
5. 하나의 파일을 여러 개의 리더로 동시 읽기 가능
6. 마커 스캐닝 없이 파일 분할 가능
7. 파일 읽기 쓰기에 일정한 메모리 용량만 필요
8. 필드의 추가나 제거가 가능한 메타 데이터는 Protocol Buffers를 사용해서 저장
7. Parquet
효율적인 데이터 스토리지와 검색을 지원하도록 설계되었으며, 칼럼 중심의 오픈 소스 데이터 파일 형식
복잡한 데이터를 일괄적으로 처리하는 기능을 더욱 향상하여 효율적인 데이터 압축 및 인코딩 방식을 제공
배치 및 인터랙티브 워크로드에 공통적인 상호 교환 형식을 제공하도록 설계
특징:
1. 무료 오픈 소스 파일 형식
2. 누구든지 사용할 수 있도록 개발
3. 컬럼 기반 형식 : 스토리지 공간 절약 및 분석 쿼리 속도 향상
4. OLAP 사용
5. 복잡한 데이터 유형과 고급 중첩 데이터 구조 지원
6. 모든 종류의 빅데이터 저장에 적합
7. 효율적인 압축과 유연한 인코딩 방식을 사용하여 클라우드 스토리지 공간에 저장
데이터베이스란?
데이터를 저장하고 쿼리 할 수 있는 중앙 시스템을 정의하는 데 사용
관계형 데이터베이스 vs 비관계형 데이터베이스
1. 관계형 데이터베이스:
- 정형 데이터를 저장하고 *쿼리 하는데 널리 사용, 행과 열!
*쿼리(Query) : 쉽게 이야기해서 데이터베이스에 정보를 요청하는 것
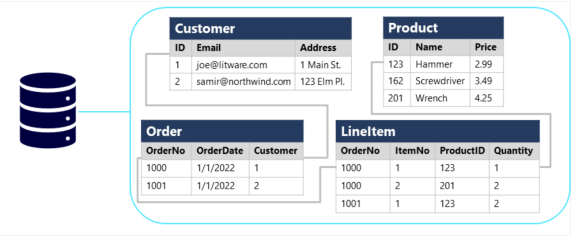
2. 비관계형 데이터베이스
1) 데이터에 관계형 스키마를 적용하지 않는 데이터 관리 시스템
2) 키-값 데이터베이스 : 각 레코드는 고유한 키와 연결된 값으로 구성되며, 값은 임의의 형식
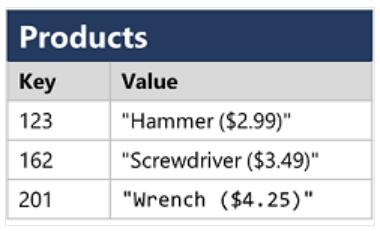
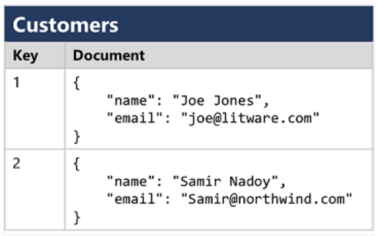
3) 문서 데이터베이스 : 키-값 데이터베이스의 특수 형태로, 값이 JSON 문서
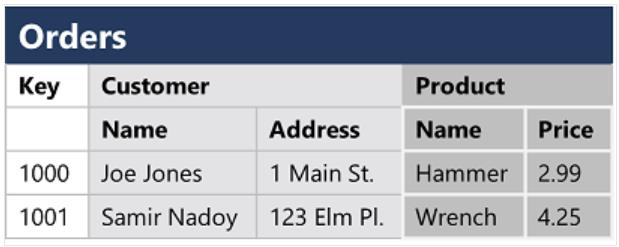
4) 열 패밀리 데이터베이스 : 행과 열로 이루어진 표 형식 데이터 저장, 열 집합!
5) 그래프 데이터베이스 : 엔터티를 노드로 저장
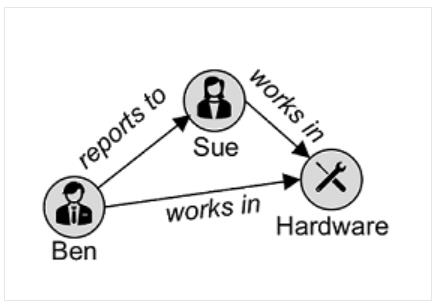
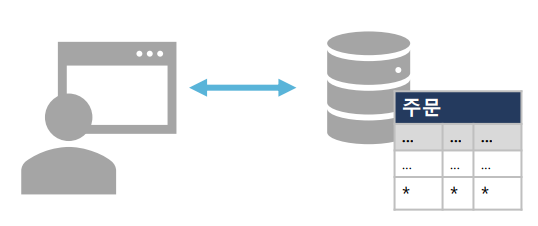
트랜잭션이란?
데이터베이스의 상태를 변화시키기 해서 수행하는 작업의 단위이다!
쉽게 말하면 거래.
트랜잭션의 특징은?
[ACID]
A: Atomicity 원자성
: 각 트랜잭션은 완전히 성공하거나 실패하는 단일 작업 단위로 처리
e.g. 윈도우 업데이트를 하면 다시시작(롤백)해야 사용할 수 있음
C: Consistency 일관성
: 데이터베이스로부터 하나의 유효한 상태에서 다른 유효한 상태로만 데이터를 받을 수 있음
e.g. 같은 파일을 여러 곳에 저장하였지만 한 곳만 업데이트하면 일관성 X
I : Isolation 독립성
: 동시 트랜잭션은 서로 간섭, 관계할 수 없다.
D : Durability 지속성, 내구성
: 트랜잭션이 성공하면 데이터 변경사항이 데이터베이스에 유지됨.
e.g. 회원가입하다가 튕겼지만 다시 재접속했을 때 입력한 정보가 있을 경우 > 좋은 내구성
트랜잭션은 대용량인 경우가 많다 → 동시에 발생하는 다수의 트랜잭션을 실행은 어떻게? → 온라인으로! *OLTP
*OLTP(Online Transaction Processing)
동시에 발생하는 다수의 트랜잭션을 실행하는 데이터 처리 유형
분석이란?
위키백과 : 복잡한 내용, 많은 내용을 지닌 사물을 정확하게 이해하기 위해 그 내용을 단순한 요소로 나누어 생각하는 것.
CS 분야 : 수학, 통계, 머신러닝을 사용해 데이터에서 의미 있는 패턴을 찾아내는 것
대량의 데이터 세트를 자세히 조사해서 새로운 인사이트, 지식 등을 발견, 해석, 공유하는 작업
분석데이터는 어떻게 처리할까?
1. 데이터 파일을 분석을 위해 중앙 *데이터 레이크에 저장
*데이터 레이크: 대량의 데이터를 저장, 처리, 보호하는 저장소(데이터가 넘치는 호수!)
2. *ETL(추출, 변환, 로드) 프로세스가 파일 및 OLTP 데이터베이스에서 읽기 작업에 최적화된 *데이터 웨어하우스로 데이터 복사
*ETL(Extract, Transform, Load) Process: 분석 목적에 맞는 형식으로 데이터를 자동으로 검색, 변경 및 준비하는 데이터베이스 프로세스
*데이터 웨어하우스: *읽기 작업에 최적화된 관계형 스키마에 데이터를 저장하는 확립된 방법(잘 정리된 창고!)
*읽기 작업: 주로 보고 및 데이터 시각화를 지원하는 쿼리
#운영 데이터 워크로드: OLTP작업에 최적화된 데이터베이스에 저장되며 읽기 및 쓰기 작업의 혼합이다.
3. 데이터 웨어하우스의 데이터를 집계하여 *OLAP(온라인 분석처리)큐브(모델)에 로드
*OLAP 큐브(Online Analytical Processing) : 분석 워크로드에 최적화된 데이터 스토리지의 집계된 유형
e.g. "강아지가 고양이에게 크게 짖는다!" > 강아지와 고양이는 상관관계 O, 고양이와 짖는다 상관관계 X
4. 데이터 레이크, 데이터 웨어하우스 및 분석 모델의 데이터를 쿼리하여 보고서 및 대시보드 생성
데이터 관련 주요 역할은 누가 있을까?
1. 데이터베이스 관리자
- 데이터베이스 프로비저닝(사전에 연결을 해놓는 형태-사전 설정 X, 청사진을 그린 형태 O)
- 데이터베이스를 관리(보안)하고, 사용자에게 권한을 할당
- 데이터 성능 모니터링 및 최적화
- 데이터 백업 복사본을 저장하고, 오류 발생 시 데이터를 복원함
2. 데이터 엔지니어
- 조직 전체에서 데이터 통합을 위한 파이프라인 및 ETL 프로세스, 인프라를 관리
- 분석 데이터 저장소 스키마 및 데이터 로드
- 데이터 정리 루틴 적용
- 데이터 거버넌스 규칙을 식별하고 *파이프라인 구현
*파이프라인 : 시스템 간에 데이터를 전송 및 변환
3. 데이터 분석가
- 데이터를 검색하고 분석하여 분석 모델링
- 조직에서 합리적인 의사 결정을 내리는 데 사용할 수 있는 데이터 정리 및 변환
- 데이터 시각화 요소 및 차트 생성
Microsoft Azure에서 데이터용 대표 서비스란?
1. 데이터 저장소
- Azure SQL
- 오픈 소스를 위한 Azure Database
- Azure Cosmos DB
- Azure Storage
2. 데이터 엔지니어링 및 분석
- Azure Data Factory
- Azure Synapse Analytics
- Azure Databricks
- Azure HDInsight
- Azure Stream Analytics
- Azure Data Explorer
- Microsoft Purview
- Microsoft Power BI
개념 따라잡기
1. 관계형 테이블의 데이터는 어떻게 구성이 되나요?
: 행과 열로
2. 비정형 데이터의 예는?
: 오디오 및 비디오 파일
3. 데이터 웨어하우스란?
: 읽기 작업에 최적화된 관계형 데이터베이스
4. 데이터베이스 관리자의 책임은?
: 데이터베이스 백업 및 복원
5. 데이터베이스 엔지니어의 책임은?
: 데이터 레이크에서 데이터를 처리하는 파이프라인 만들기
6. 데이터 분석가의 책임은?
: 대시보드 및 보고서 만들기
7. Azure Data Factory를 사용해서 ETL 프로세스를 위한 데이터 파이프라인을 정의하는 역할은?
: 데이터 엔지니어
8. 데이터 파이프라인, SQL 분석 및 Spark 분석을 구현하는 데 사용할 단인 서비스는?
: Azure Synapse Analytics
'Sooin's Equipment > etc. React, Blender, Azure DP-900' 카테고리의 다른 글
| [Azure DP-900] 예제 및 풀이(72문제) (1) | 2024.01.19 |
|---|---|
| [Azure DP-900] 3. Azure에서 비관계형 데이터 탐색하기! (2) | 2024.01.19 |
| [Azure DP-900] Azure SQL 설정하기(기초) (0) | 2024.01.19 |
| [Azure DP-900] 2. Azure에서 관계형 데이터 탐색하기! (2) | 2024.01.19 |
| [Azure DP-900] DP-900이란? (0) | 2024.01.17 |



